I know what you are thinking after reading our first two parts of this series: What dataloggers should I buy to measure my climate? There are loads out there and some are pretty expensive!
Here’s the thing: What makes dataloggers expensive is accuracy, especially when it comes to measuring relative humidity. You can buy pretty cheap models, but what makes them cheap is usually cheap sensors. Now, you probably wonder how bad it is to have a cheap sensor. As nearly always, it’s a “depends”. Depending on what? Depending on how stable your “room climate” (although we already saw that there is no such thing) is and how accurate you need your measurement to be.
One thing you have to know is that sensors have a range they operate in, humidity sensors usually and logically between 0 and 100% relative humidity. Within this range they might vary in accuracy. Humidity sensors are typically most accurate in the middle range around 50% rH and become less accurate at the edges under 10% or over 90% rH, they also might become less accurate in very cold or very hot surroundings. Usually, you find these error ranges as graphs in the datasheet of each sensor or device.
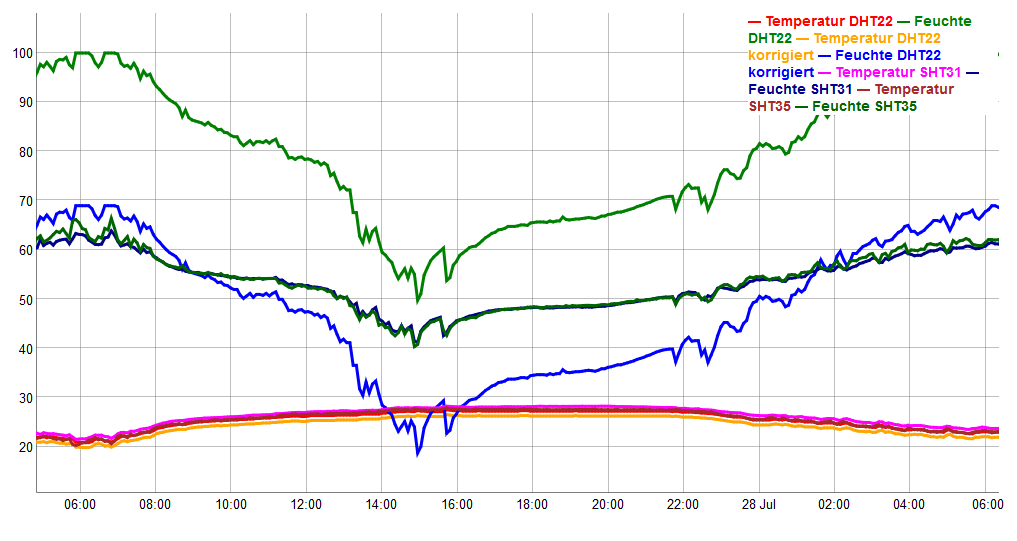
That’s pretty theoretically, so I made a test to show you what this can mean (in retrospective I should have used a more diverse set of colors for the diagram, my apologies for that). I put in the same spot three sensors:

DHT22 (light green), corrected DHT22 (blue), generic SHT31 (dark blue), Sensirion SHT35 (green)
- A pretty cheap DHT22/AM2302 1 which is a very common temp/rH sensor in the maker/microcontroller scene and which you will find frequently in DIY devices. It is given with a normal accuracy of +/- 2% RH and +/- 5% RH maximum discrepancy (in which range it reaches this maximum discrepancy isn’t given).
This is the light green line. - A mid-priced generic Chinese version of a Sensirion SHT31 2 which you will also find in more refined DIY projects. It is also given with a +/- 2% RH accuracy.
This is the dark blue line. - A high-priced original Sensirion SHT35 3 which you will find in professional devices. It is given with an accuracy of +/- 1.5 % RH in a range between 0 and 80% relative humidity, which means it becomes less accurate above these values.
This is the green line. - In addition, you will find a blue line: This is the linear correction of the DHT22 sensor which is based on the measurements I did with this sensor compared to an Assmann psychrometer. I found the DHT22 was 31 percentage points off the “real” relative humidity I found with the Assmann at 55%. So, I subtracted 31 from the value the DHT22 measured. 4
So, what does the graph show us and what can we learn from it?
All sensors are pretty much the same when it comes to temperature. This tells us that if we only want to measure temperature, we can go with a cheap device.
When it comes to humidity, things become really interesting:
- The original DHT22 readings show a much too high humidity, something we already expected because of our measurements with the psychrometer. Naturally, as the sensor can only read 100% max, the lines are cut at 99.9%. As our correction of the sensor is mainly a linear subtraction, it transfers the straight line to 68.9% for our corrected values in these cases (blue line).
- The expensive original SHT35 and the cheaper generic SHT31 are not really far apart. When humidity crawls towards the 70% and over it, it seems that the cheaper one (dark blue line) measures a little less humidity than the expensive one (green line). 5
- What is really funny is that the cheap sensor seems to have a tendency to over-dramatize events. As we take a closer look at a drop (and later rise) in humidity on July 27 the DHT22 shows a dramatical decrease from 100% in the morning down to 49.7% at 3 p.m. Its corrected version sees an equally dramatic event from 68.9% to 18.7%. As we take a look at the other two sensors nothing this dramatic happens. The most expensive one sees a drop from 66.3% to 40.7%. Still a mild catastrophe if this were a gallery or storage room (it wasn’t), but a huge difference to have a 25% drop than a 50% drop.
A close look at July 27
Especially the last point tells us a lot about cheap and expensive dataloggers. Not because cheap devices necessarily contain an old, beat up DHT22, but because it shows us the general problem with sensors: they are not necessarily acting linear. They’ll need adjusting.
Now, every adjusting is an expensive step. Devices are adjusted to reference points which means the manufacturer does more or less what I did with the DHT22: they measure it against a calibrated source (i.e. a salt solution) and then adjust the output accordingly.
If it is a cheap device it might be only adjusted to one reference point, resulting in what we see in the DHT22. Just because it was 31 percentage points off at 55%, this isn’t necessarily true for the whole range. Instead, it is very unlikely for a sensor to react linear throughout the whole spectrum. It will react differently for different humidity ranges. This is why expensive devices are measured to more reference points and calibrated accordingly, resulting in much more accurate readings throughout the whole range.
I assume that the generic SHT31 was also only tested against one reference point and that the difference we see in the readings against the original Sensirion when the humidity rises is already a sign of it, but as it is still within the possible error range, I can’t prove that.
For me personally, I wouldn’t use DHT22 anymore, for obvious reasons. I can live with the generic SHT31 for cases where I need to get an idea of a setting and in less problematic areas. I’d always go with the high-priced original parts if I have to depend on the readings for loans or critical storage environments.
So, more generally speaking: can I cut costs by buying a cheap device? Yes, if you just have to measure temperature. And yes, if the only thing you need is a rough idea of what happens in regards of rising and dropping or the humidity, but not detailed values. You have to be aware of the fact that it might show a more dramatic drop than what actually happened as well as it is thinkable that it shows you a less dramatic change than what actually happened.
You might want to turn to high quality products when it comes to your more critical applications and it’s always a good idea to take a critical look at the datasheets to know what you are buying.
May your storages and galleries always have a nice and stable climate!
Angela
- See full datasheet here: https://www.sparkfun.com/datasheets/Sensors/Temperature/DHT22.pdf ↩
- See details here: http://vi.raptor.ebaydesc.com/ws/eBayISAPI.dll?ViewItemDescV4&item=162728071099&category=65460&pm=1&ds=0&t=1509175725000&ver=0 ↩
- See full datasheet of the Sensirion SHT 3x series here: https://www.sensirion.com/de/umweltsensoren/feuchtesensoren/digitale-feuchtesensoren-fuer-diverse-anwendungen/ ↩
- To be fair, I didn’t treat this particular sensor nice in the past years, so it was already a bit old and used. I have found a lot of DHT22 more close to original humidity values and usually don’t use sensors that are more than 2% off the mark for fieldwork. But as you read on, you will understand why I don’t use them for anything critical anymore. ↩
- If I take the most extreme discrepancies, they are in the range of 2-3 percentage points, which would still mean they are in their acceptable error range if I grant one sensor to err on the plus and one to err on the minus side of its spectrum. ↩










 I’m all excited that I was chosen to speak at the European Registrars Conference in London, taking place November 17-19 (see full program here:
I’m all excited that I was chosen to speak at the European Registrars Conference in London, taking place November 17-19 (see full program here: 